
BADAS 2.0
The world's best incident prediction model, period.
BADAS 2.0 is a world model that has internalized physics and causality. We trained it on 2M real-world driving clips. We fine-tuned NVIDIA's COSMOS on the same data. BADAS wins – at 91x fewer parameters. We publish everything. Try it yourself.

.svg)













Run BADAS 2.0 on Your Own Video
Watch the world's best incident prediction and understanding model in action.
A New Standard for Road Safety

0.994 AP vs 0.940. Same Data.
Different Architecture.
We fine-tuned NVIDIA's COSMOS-Reason2-2B on the exact same 2M training clips. BADAS 2.0 achieves 99.4% AP. COSMOS achieves 94.0%. At 91x fewer parameters, our smallest model still beats their largest. We publish our benchmarks and invite direct comparison.
COSMOS-BADAS = NVIDIA COSMOS-Reason2-2B fine-tuned on the same 2M Nexar training clips used by BADAS 2.0.



We Published The Benchmarks. Your Move.
AUC and AP across 10 scenario groups (888 clips, sliding window). BADAS 2.0 leads in every category. Best per row in bold.
2.0
2.0
2.0
1.0
Open
Reason2
Pro
VL-2B
Single-window mean AP over three lead-time thresholds (1,344 clips). BADAS 2.0 improves mAP from 0.925 to 0.940 while cutting the false positive rate by 74%.
On the internal test set, BADAS 2.0 cuts the false positive rate from 17.7% (v1.0) to 4.6% – a 74% reduction with no loss of recall.
Fraction of collision events detected before they occur (888 clips, 10 scenario groups, threshold 0.75).
AUC and AP on three public academic benchmarks using ego-centric re-annotation. Best per column in bold.
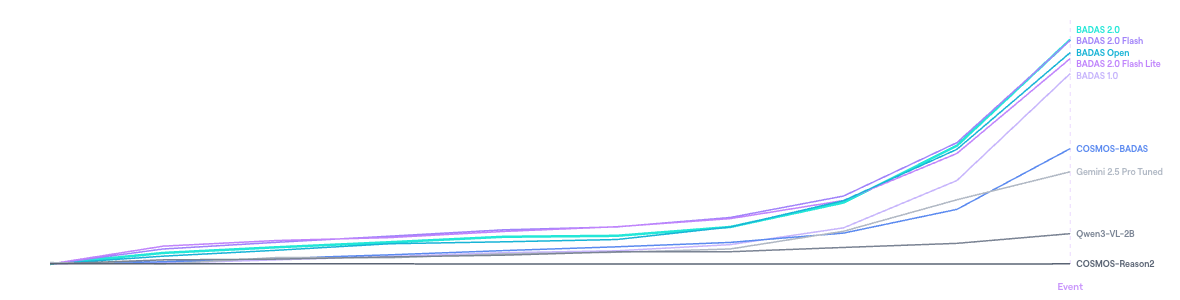
Average collision probability over normalized pre-event time (0% = start, 100% = event). Each clip's timeline is scaled independently, so clips of different lengths are comparable. Positive clips only. BADAS models ramp up sharply; competitors stay flat.
.png)
.png)
.png)
.png)
.png)
Reading this chart: For every positive clip, each model's prediction timeline is normalized so 0% = first prediction and 100% = labeled event. Predictions are binned into 10 equal intervals then averaged across clips. Curves are baseline-normalized per model so the y-axis shows each model's rise above its own floor. A steep ramp means confidence increases sharply as the event approaches; a flat line means the model outputs a near-constant score regardless of proximity to collision.




See What the Model Sees.
Know Why It Acts.
For the first time, a collision anticipation system explains itself. Attention heatmaps show where the model looks. BADAS-Reason tells you what to do and why. OEMs get integration confidence. Insurers get audit trails. Fleet operators get actionable alerts.



Three Models. From Cloud to Edge.
GPU and CPU.
Cloud analytics teams run the full 300M model. Edge ADAS integrators deploy BADAS 2.0 Flash. IoT manufacturers ship BADAS 2.0 Flash Lite. Same architecture, same training, same world model – scaled to your needs.
- SOTA performance across all metrics
- Best mTTA and early warning recall
- Expert in rare long-tail cases
- 34ms on A100 · 41ms on Jetson Thor
- End-device-optimized model
- Expert in false alarm prevention
- Outperforms BADAS 1.0 on every metric
- 4.8ms on A100 · 12.5ms on Jetson Thor
- Ultra-light model for IoT devices
- Optimized for GPU and CPU inference
- Rivals BADAS 1.0 at 14x fewer params
- 2.8ms on A100 · 5.9ms on Jetson Thor


V-JEPA2 Validates the World Model Thesis.
BADAS 2.0 is built on V-JEPA2 – the architecture Yann LeCun proposed as the foundation for world models and physical AI. Latent-space prediction optimizes for physical causality, not visual reconstruction. BADAS 2.0 is the proof that this thesis works for safety-critical applications.

BADAS 2.0 fine-tunes a V-JEPA2 ViT-L backbone (300M parameters, 24 transformer layers) end-to-end on 16-frame clips at 256×256 resolution and 8 fps. A future-prediction branch estimates the scene 1 second ahead and concatenates it with the current clip, giving the prediction head access to both present evidence and near-future dynamics. Domain-specific SSL pre-training on 2.25M unlabeled Nexar edge device clips is the critical enabler for the distilled edge variants.
~200,000 Labeled Videos. Zero Synthetic Data.
Most collision anticipation models are trained on synthetic data or small academic datasets. BADAS 2.0 is trained exclusively on real-world edge device footage from Nexar's network – the largest ego-centric driving dataset ever assembled for this task.
BADAS 2.0 is trained on ~200,000 labeled videos (~2M windowed clips) – a 5x expansion over v1.0. The corpus is assembled through intelligent data mining: BADAS 1.0 runs as an active oracle over millions of unlabeled Nexar drives, surfacing high-risk clips for human review.
The result: 99.4% AP at 4.6% FPR – a 58% reduction in false alarms over v1.0 on the sliding-window benchmark, with gains across all subgroups including the hardest long-tail categories.





Beyond the Road.
Any machine with a camera that moves through the physical world can use BADAS to predict what happens next – not because we trained it on every environment, but because it learned how the physical world works. Warehouses, sidewalks, aerial corridors, factory floors – if it has a camera and it moves, BADAS can make it intelligent.






Talk to us about your environment.
Tell us what your machines see and we'll show you what BADAS can predict.
Get in touch →


Where BADAS Is Used Today
.svg)
AV Program Development
.svg)
ADAS Supplier Integration
.svg)
Fleet Safety
.svg)
Insurance Underwriting

Frequently Asked Questions
Best Collision Prediction
Model on the Planet.
The Bar Is Set.
We publish our benchmarks. We built a public demo. If you think your model is better – show us. If you want to deploy the best – talk to us.
Get In Touch
