Collision warnings have a trust problem
_0003%20(1).png)
Every fleet operator knows the story. You activate a collision warning system. For the first week, drivers pay attention. By the second week, false alarms have become relentless — phantom alerts at routine intersections, lane changes, overpasses. Drivers stop listening. Dispatchers waste hours chasing false positives. Eventually, the system gets turned off.
The technology didn’t fail at detection. It failed at trust. And it failed at trust because it was built on the wrong foundation: pattern recognition. Every collision warning system until now has worked the same way — detect a visual pattern that looks like danger, fire an alert. The system could tell you danger was present. It could not tell you what was about to happen, why, or what to do about it.
The output was a score. A number between 0 and 1. No context. No evidence. No explanation. For research, that was acceptable. For deployment in vehicles, fleets, and insurance products, it was a barrier.
The gap between what’s possible and what’s deployed
As autonomous and semi-autonomous vehicles move from pilot programs to production, the limitations of reactive collision systems become more consequential. OEMs need safety layers they can explain to regulators. Insurers need event trails they can audit. Fleet operators need coaching built on specific, verifiable incidents — not mystery alerts.
And across the industry, the same question keeps surfacing in procurement conversations: “When the system fires, can you explain why?” For every collision system on the market, the honest answer has been no.
Introducing BADAS 2.0
BADAS 2.0 is a collision anticipation world model built on V-JEPA2 — the architecture behind Yann LeCun’s vision for physical AI. It does not match visual patterns. It has internalized how objects move, interact, and collide, trained on 178,500 labeled videos — approximately 2 million clips — captured by Nexar’s fleet of 350,000+ dashcams. Zero synthetic data. Every frame from real roads, verified by human annotators.
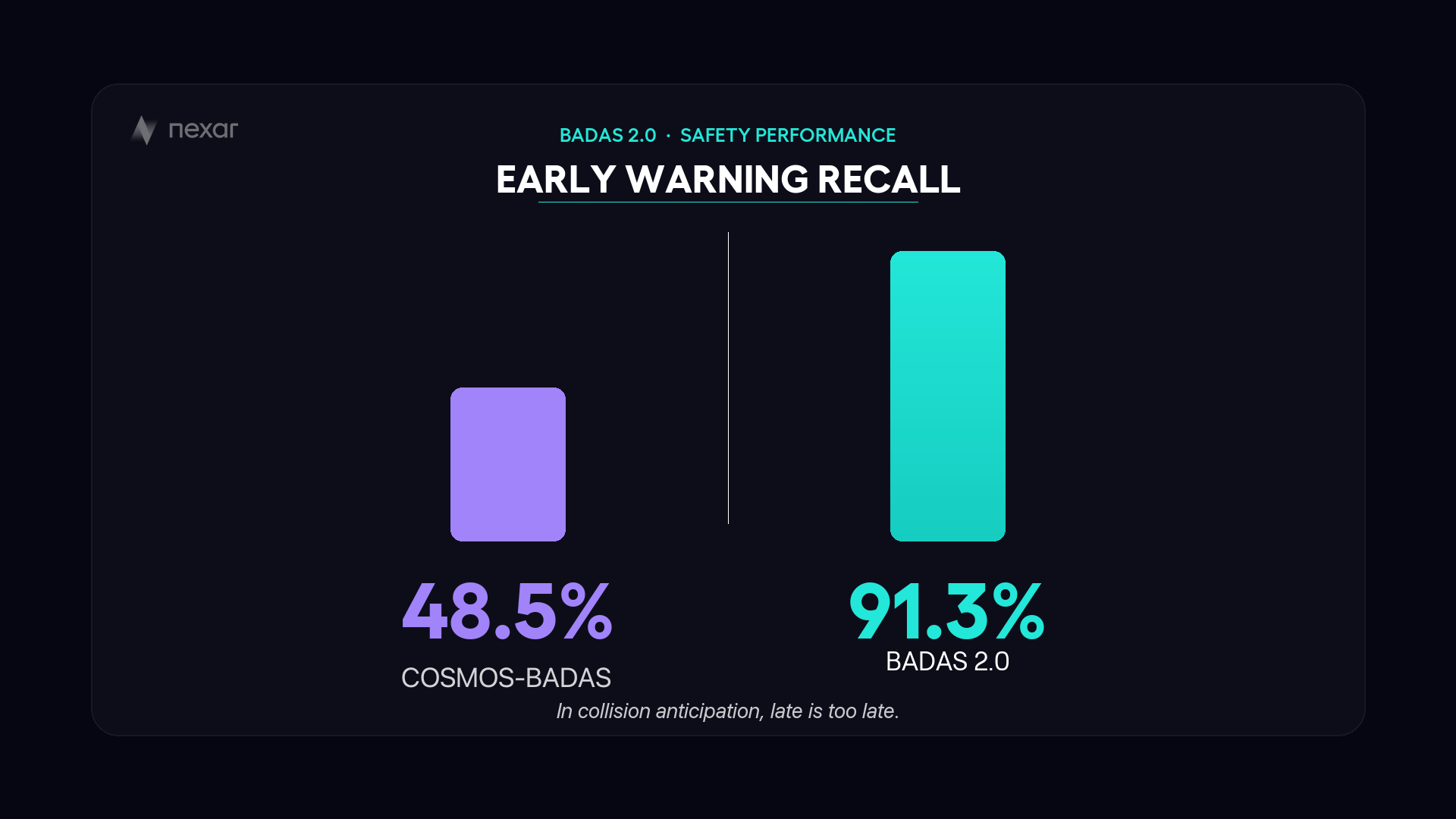
The system anticipates collisions before they happen. 91.3% of its alerts arrive before the moment of impact — early enough for the driver to react. It explains every prediction in plain language: “Pedestrian entering lane from the right. Brake immediately.” And it produces attention heatmaps showing exactly which objects and trajectories drove the prediction.
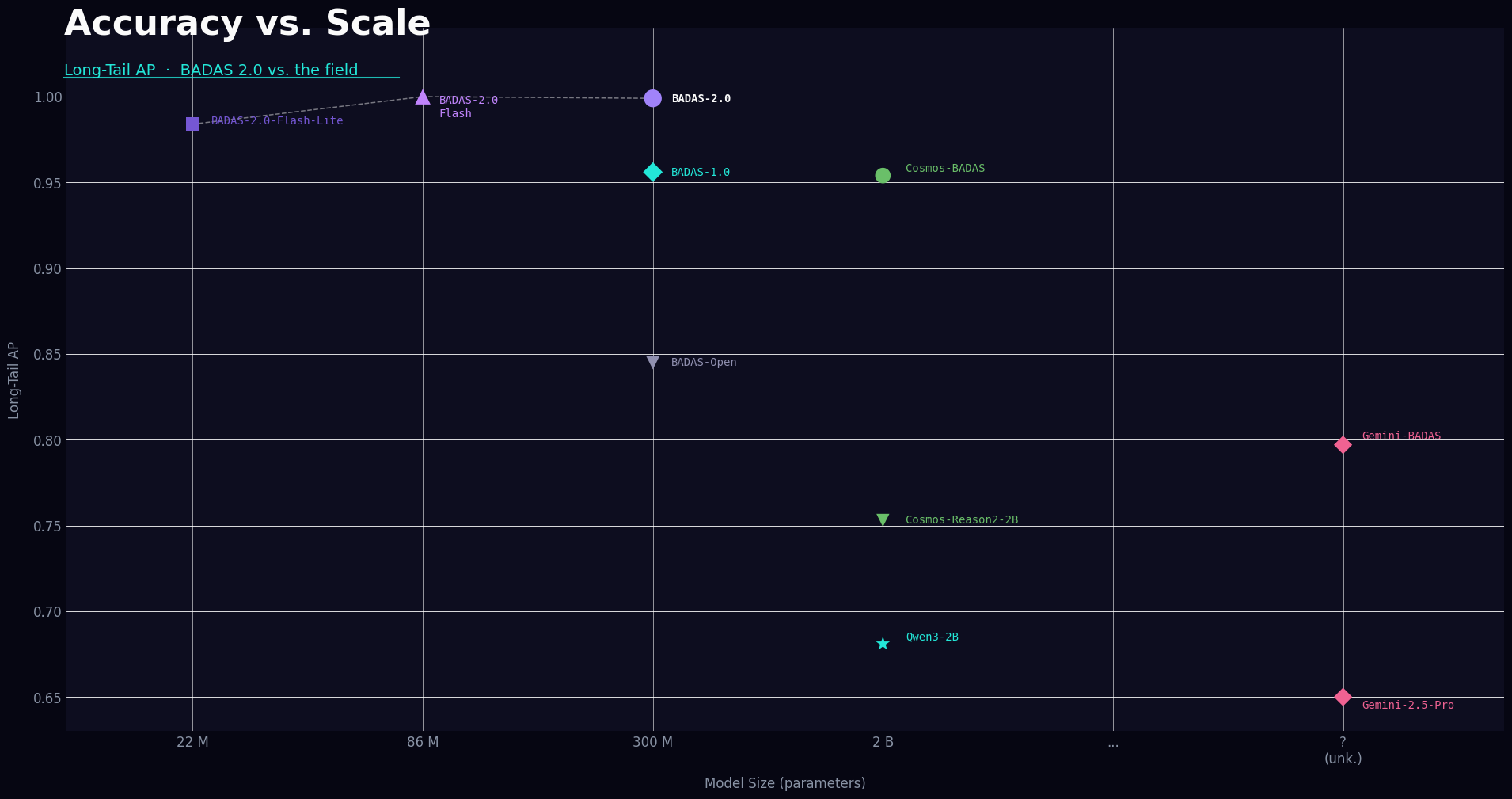
BADAS 2.0 ships as a family of three models, all distilled from a single architecture: the full model at 300M parameters (34ms inference), Flash at 86M (4.8ms), and Flash Lite at 22M (2.8ms). All run within the real-time budget on both cloud GPUs and embedded hardware including NVIDIA Jetson Thor. Flash Lite runs on dashcam hardware already installed in millions of vehicles.
What makes this different
Three things separate BADAS 2.0 from every collision system that came before it.
The data infrastructure. BADAS 1.0 was deployed as a mining oracle — running across millions of unlabeled drives to surface the rarest, hardest scenarios for the next generation to learn from. Nexar Atlas, the company’s geospatial intelligence platform, targeted specific gaps: animal crossings, fog, nighttime intersections, passing maneuvers. The model that shipped yesterday trained on data surfaced by the model that shipped last year. That flywheel runs on 100 million fresh miles every month.
The architecture. Autoregressive vision-language models like NVIDIA’s Cosmos-Reason2 reconstruct what a scene looks like. BADAS 2.0 predicts what will happen next in latent representation space. When both were fine-tuned on identical training data and evaluated on the same benchmark, BADAS 2.0 at 300M parameters achieved a Kaggle mAP of 0.940 while Cosmos-Reason2 at 2 billion parameters reached 0.859. On the long-tail benchmark, Flash Lite at 22M parameters — 91× smaller — achieved higher average precision than Cosmos-Reason2 at 2B (0.984 vs 0.941).
The explainability. BADAS-Reason, a fine-tuned vision-language model built on Qwen3-VL-4B, generates structured hazard descriptions and driver action commands from BADAS attention outputs. Fine-tuning reduced perplexity by 87% and improved action-match accuracy 3.6× over the zero-shot baseline. Every prediction is auditable. Every alert is traceable.
The numbers
.png)
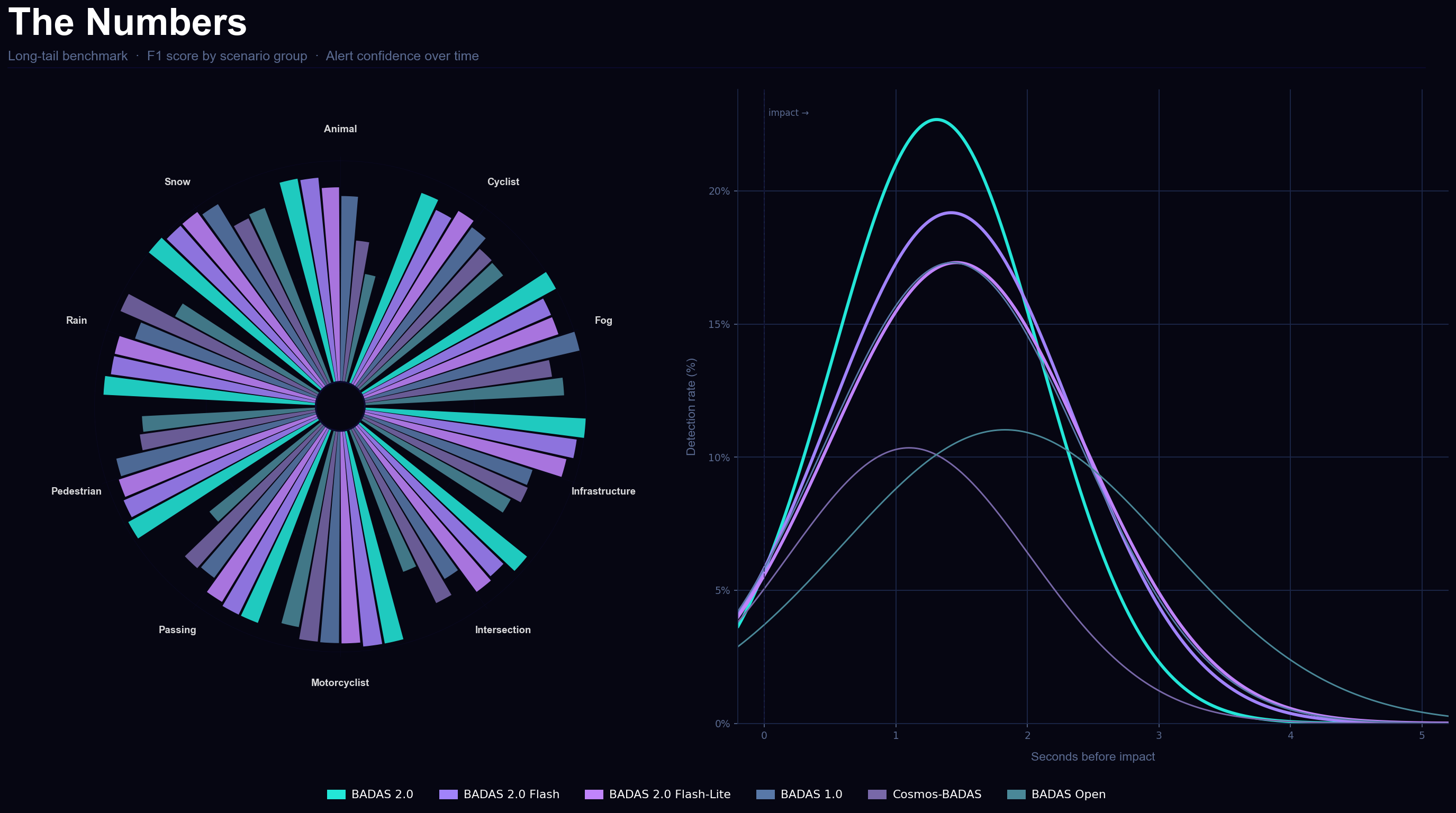
BADAS 2.0 was evaluated across multiple benchmarks. On the Nexar long-tail benchmark — 888 manually verified clips across 10 scenario groups including fog, snow, animal crossings, nighttime pedestrians, and passing maneuvers — the model achieves 99%+ average precision on every category. On the Kaggle competition benchmark, mAP improved from 0.925 (BADAS 1.0) to 0.940 (BADAS 2.0). False positive rate dropped from 10.9% to 4.6% — a 58% reduction with no loss of recall.
The most challenging category remains animal crossings, where animals frequently appear with near-zero warning time regardless of model capacity. The fundamental constraint is scenario geometry, not detection quality. Nexar reports this limitation transparently alongside all results.
Inference code and evaluation benchmarks are publicly available. The challenge is open.
What this means for you
For fleet operators: collision anticipation that runs on hardware you already own, with less than 5% false positives and plain-language explanations your drivers and safety managers can act on.
For OEMs: a model family that fits your compute budget at every deployment target — cloud, edge GPU, or dashcam — and explains itself to regulators.
For insurers: an auditable event trail with attention heatmaps and natural language reasoning. Evidence, not a black box.
For AV developers and the research community: published benchmarks on identical training data. Independent evaluation welcomed.



